Ӎ�w�ǻ𣬑{ʲô�ɞ�����߿���AI��ģ�ͣ�
2025-06-09 15:26:29�W�j�YԴ

�߿���AI��������׃��Խ��Խ�ߡ�����֮�ȣ����AI�O���o��ϵ�y��AI�o��醾����¼��g���ڲ������á�����֮�⣬AI��ģ�͂���ƴ���}Ҳ������ÿ��߿���“������Ŀ”��
�����겻ͬ������AI�߿���ƴ������׃�������������ģ�͡����^��ȥ��Ĵ��Z��ģ�ͣ��������ģ���چ��}���⡢˼������Լ��ش�ݔ���϶����߃��ݣ�˼�S朵ļ���Ҳ�˂����������ؿ�����ģ�͵�˼���^�̡�
ȥ����Z��ģ�ͻ��r������ģ��߀�o���ʴ_�����}�⣬�������F�������}�F�������@�N��r�Ѵ��p�١��c��ͬ�r���������������ģ���ڔ��W߉˼�S�����ϵ�������ģ�͵ĸ߿����W�÷҄��¸ߣ�ӿ�F��Խ��Խ���“AI��Ԫ”��
�^ȥ���죬���в���ý�w���Ȍ���ģ�͵ĸ߿����}����չ����Ȝy�u�����w�Z�ġ����W��Ӣ�Z�ȶ�����Ҫ��Ŀ���Y���@ʾ�����a��ģ�͵��M����Ȧ���c���ڶ��ý�w�Ĵ�ģ�߿��M�u�У����a��ģ�͵Ĵ��}ˮƽ�z��������OpenAI���µ�����ģ�ͣ���DeepSeek R1��Ӎ�w�ǻ�X1�Ȟ�����ć��a��ģ�ͣ����nj��F�ˌ���������ģ�͵ķ�����
�Խ������µ���ý�w“늏S”ᘌ��߿��Z�����ĵĜy�u������늏S�xȡ�˸߿�֮���J�^�y��ȫ��1���Z�������M�Мy�u��DeepSeek��ͨ�xǧ�����ֹ�����������һ�ԡ��vӍ��Ԫ�Լ�Ӎ�w�ǻ��6���������a��ģ�ͅ��c����ͬ�r�e��Ո�����I�����Z�Ľ̎������ң��팦����ģ�����ɵĸ߿�������һ��֡��u��Ҏ�t���λ�̎����Ҹ��Ԫ����u�֣����ȡƽ���÷֡�
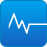
������λ���ҵ�����u�ֿ��Կ���������Ӎ�w�ǻ�DeepSeek���ֹ������Լ�ͨ�xǧ���Ŀ��ģ�Ͷ��@����50�����ϵ�ƽ���֣�����Ӎ�w�ǻ���ƽ����53�����е�һ��DeepSeek��52.5�����еڶ�λ���vӍ��Ԫ������һ�Ԅt�����÷��^�͡����^��6 ���ģ�;��ܜʴ_ץס�}�⣬���@�}����”��Ĭ�c�l”���Pϵչ�_Փ����

�C�ό�����Ҋ��Ӎ�w�ǻ�DeepSeek�÷��^�ߵĹ�ͬԭ����������}�⡢������̣�ͬ�r߉�b�ܡ�Փ�����������˼�����c��Ⱦ�������÷��^�͵�ģ�̈́t�����������½Y�����ز��x���Լ�Փ��߉�ϴ������@�̰塣
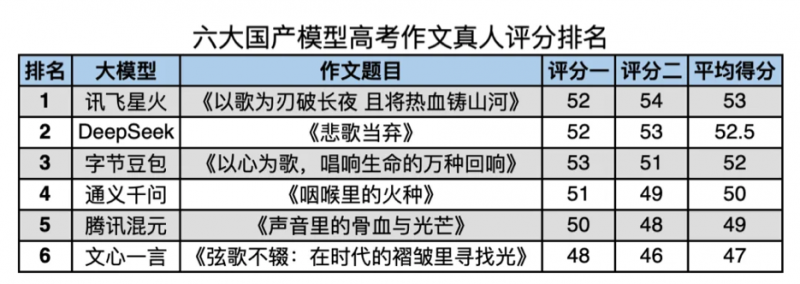
���Č���֮�⣬Ҳ��ý�w���T�yԇ�ˎ��ģ�͵�Ӣ�Č���ˮƽ���¾����x���˽���߿�Ӣ�Z�������������}Ŀ���y�uDeepSeek R1��ChatGPT o3��ͨ�xǧ�� Qwen3���vӍ��Ԫ T1��Ӎ�w�ǻ� X1���ٶ����� X1��6���������ģ�ͮaƷ��ģ�ʹ��}�Y�����¾�����Ո��������ʮһ�WУһ��УӢ�Z�ώ��n�����������ЌWӢ�Z�̎��w�ļεȃ�λ���ҽ̎�����������߿��u�֘˜ʌ���ģ���M�д�ֲ��c�u��
�ĵ÷ֽY���п��Կ�����Ӎ�w�ǻ�X1��DeepSeek R1�ٶȌ��F������ģ�͵ķ������քe������һ�����������У�Ӎ�w�ǻ�X1����ȫ����߷�19.5�֣�DeepSeek R1 �� 0.5 ��֮��λ���������OpenAI o3�����S�Dz�̫�m���߿����}�˜ʣ��H����14.5�֡�
�n�����ώ���ʾ�����������ģ�Ͷ����ڃ��ݷ�������Ҫ�c����Ɍ����΄ա����ǣ����ݼ������١�����߉�Pϵ�������^�c���_�������c�����Եȷ��棬��e���^�����磬�÷��^�ߵ�Ӎ�w�ǻ�X1�Լ�DeepSeek���ܜʴ_�����}�⣬�Z�Ծ��ʣ��Y����֔��ͬ�r�ھ䷨�Y������ʽ��׃�����÷��^�͵�ģ��Ҫô���Z�������~�ϴ���Ƿȱ��Ҫô��Փ��߉��㕽ӵIJ���o�ܡ�
������“��”�IJ��֣��҂��ف����������������������ģ���ڔ��W�����ϵ��^�����߿����W��ԇ�Y�����죬ᘌ����W�¸߿�1�����Ƽ�ý�w IT ֮�Ҍ����������������ģ���M���˙M�u����K�Y�����£�
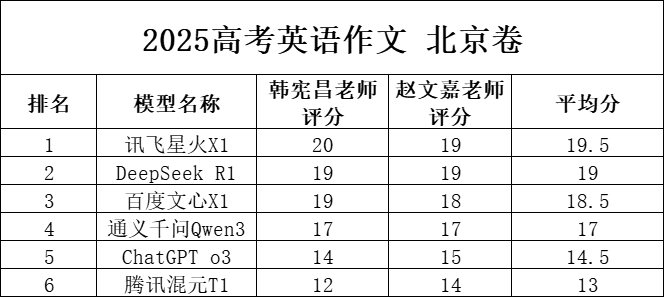
�ڸ߿����W����K�÷��У�DeepSeek�Լ�Ӎ�w�ǻ���Fͻ���������Ѕ�ِ���������ģ����Ψ���@��140�����ϵĴ�ģ�ͣ��I��һ���������ģ�ͣ����Ӵ�ģ�߿����W���}��һ��ꠡ�����������˿����У�140������Ҳ����ȫ�������ȵ�“피�”ˮƽ��
�@Ҳ���������ģ�͵ă������ڣ����^�ڸ�ƫ�����^ɫ�ʵ����Č��������W߉�����������������ģ�͵��L̎��IT ֮���ڜy�u���e�ᵽ����ȥ��������Ĵ��Z��ģ����ȣ������������ģ�͵Ĕ��W�����������@������
�C�ϲ�ͬý�wᘌ��Z�������ƵęM�u���}�Y����Ӎ�w�ǻ�X1�Լ�DeepSeek R1�Խ^�����ݷ��Ӵ�ģ�߿����}�ĵ�һ��ꠣ����У�Ӎ�w�ǻ�X1�������Z��Ӣ���ƾC�ϵ�һ�ijɿ����ɞ�2025������߿�ͬ�rҲ����߿��ć��a��ģ�͡�
Ӎ�w�ǻ�X1��2025�߿��еij�ɫ���F���x���_�ƴ�Ӎ�w20������ڽ����I���������ƴ�Ӎ�w�LJ������������˹����ܼ��g�x�ܽ����ĿƼ���˾֮һ�����F�˸��w�ČWУ�̌W���̎��lչ���ǻۿ�ԇ�����|�����������W���Ƚ���ȫ�����ĮaƷ�����գ�ͬ�r�������ć��ҡ�ʡ���С��h���^�����WУ����ͥ���ǻ۽����wϵ��
AI��ģ�͕r����Ӎ�w�ǻ����m�˿ƴ�Ӎ�w�ڽ����I����I�ȃ��ݡ�����ģ���ϣ�����ȫ���a����Ӗ����Ӎ�w�ǻ��ģ�͇����I�ȣ��ǻ�X1������ģ�ͅ������ȘI��ͬ����һ������������r�£����F���wЧ������OpenAI o1��DeepSeek R1��
2025 ��߿��mȻ�ܿ��Ҫ�����Ļ������ģ�͂�֮�g��“�߿�”�Ԍ��^�m����AI�x�ܽ���Խ��Խ����Į��£��������ģ�͵��M�����҂������˸���AI+�����Ŀ����ԡ�
��ƽ�_���l����Ϣ�ă��ݺ͜ʴ_�����ṩ��Ϣ��ԭ��λ��M�������Г���ȫ؟�Σ�